文字コードの話は正確にやろうとすると大変なので適当に書いてみる。
文字集合:文字を集めたもの
JIS X 0208
Unicode
符号化方式:文字集合に番号をつけたもの
ISO-2022-JP
EUC-JP
Shift_JIS
コードセット
文字集合の集合、EUC-JPではASCII+JIS X 0208+その他
実際の文字コード:1バイト
US-ASCII:0から127まで使う標準的な半角英数文字と制御コード
128から255までをどう使うかでいくつかの文字コードがある
ISO-8859-1はドイツ語のウムラウトとかアルファベットの上に何らかのマークがつく文字を収録していてヨーロッパでは基本の文字コード、WindowsではWindows-1252ともいわれる。
ISO-8859-5はキリル語(ロシア語)の文字だがあんまり使われずKOI8-Rが使われるらしい。
実際の文字コード:2バイト以上
欧米件は文字数が少ないので1バイトでよかったが、漢字圏では足りないので2バイト以上になる。
Shitf-JIS:最大2バイト
もともと日本語はJIS X 0201でASCIIでつかってなかった領域にカタカナを収めて1バイトで使っていた。
漢字が表示できるようになってからは、この1バイトの使ってない領域を2バイト文字へ移行する制御コードとして使い、2バイトを利用して漢字を表現していた。
Cプログラムなどで問題になるのは2バイト文字の2バイト目が\などになった場合である。例えばパスを¥で区切るプログラムを単純に作っているとこの2バイト目の¥に引っかかっておかしくなってしまう。
EUC-JPやUTF8では2バイト目以降のバイトにこれらのASCIIは入らないのでこのような問題は起こらない。
ソフト業界が国際化してからはWindowsではUTF16を使いLinuxではUTF8を使うことが多い。UTF16は基本的に2バイト固定なので文字操作はしやすいが欧州圏からみるとメモリがもったいない。
Unicodeでは¥とバックスラッシュは区別されているが、JIS X 0201のASCII部分も実は若干変わっていてバックスラッシュのところに¥を割り当てている。文字コード変換などでShift-JISからUnicodeに変換したときもし¥がそのままUnicodeの¥になってしまうと困るので運用上はASCII部分は変換しない慣習になっている。逆にUNICODEの\(U+00A5)からShift-JISに変換した場合はバックスラッシュに変換してしまう。よってさらにこれをUNICODEに変換したら元の文字列と同じにならないことになる。日本語環境では今後もバックスラッシュにお目にかかることはないのだろう。
UTF8で書いていて本当にバックスラッシュを表示したい場合はHTMLなら
|
1 |
<span lang="en" xml:lang="en">\</span> |
と書けばいいようだ。実際書いてみる→\
Windowsでのプログラム
Windowsでは文字コードをコードページという言い方をしているようだ。
|
1 2 3 4 5 6 7 8 |
int MultiByteToWideChar( UINT CodePage, // コードページ DWORD dwFlags, // 文字の種類を指定するフラグ LPCSTR lpMultiByteStr, // マップ元文字列のアドレス int cchMultiByte, // マップ元文字列のバイト数 LPWSTR lpWideCharStr, // マップ先ワイド文字列を入れるバッファのアドレス int cchWideChar // バッファのサイズ ); |
MultiByteというのは日本語環境ならShift-JISというように、Unicode以前の2バイト以上文字列のことでWindows98とかのころのOSのデフォルトの文字コードのことだろう。
WideChar、ワイド文字とはUTF16をさす。
第一引数のCodePageは入力文字列のコードページだがCP_ACPを指定すればOSのデフォルト設定が使われ日本語WindowsならShift-JIS(codepage932)になると思われる。もっとも昨今のWindowsはこのデフォルトのコードページを変えられると思われそれは、言語設定の非UNICODEアプリの設定になると思われる。
ロケールとの関係
Cライブラリにはmbstowcsがあり、これで変換できる、LC_CTYPEがマルチバイト文字列をあらわしている。
コンパイラ
最近のコンパイラはUNICODEで保存されていてもOKなのでリテラル文字列を国際化できる。一般にはコードはASCIIのみがよいとされているものと思われるが。
VC2008ではファイルの保存で文字コードを選択できるので以下のようなコードが書ける。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 |
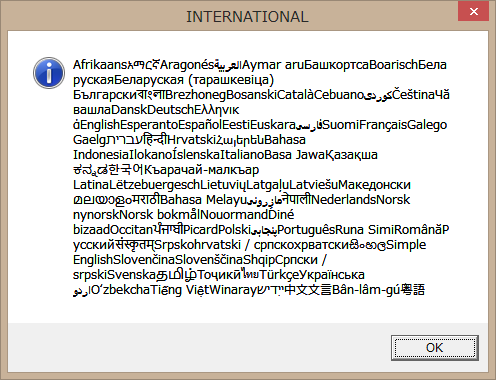
#include #include int _tmain() { MessageBox(NULL, L"Afrikaans" L"አማርኛ" L"Aragonés" L"العربية" L"Aymar aru" L"Башҡортса" L"Boarisch" L"Беларуская" L"Беларуская (тарашкевіца)" L"Български" L"বাংলা" L"Brezhoneg" L"Bosanski" L"Català" L"Cebuano" L"کوردی" L"Čeština" L"Чӑвашла" L"Dansk" L"Deutsch" L"Ελληνικά" L"English" L"Esperanto" L"Español" L"Eesti" L"Euskara" L"فارسی" L"Suomi" L"Français" L"Galego" L"Gaelg" L"עברית" L"हिन्दी" L"Hrvatski" L"Հայերեն" L"Bahasa Indonesia" L"Ilokano" L"Íslenska" L"Italiano" L"Basa Jawa" L"Қазақша" L"ಕನ್ನಡ" L"한국어" L"Къарачай-малкъар" L"Latina" L"Lëtzebuergesch" L"Lietuvių" L"Latgaļu" L"Latviešu" L"Македонски" L"മലയാളം" L"मराठी" L"Bahasa Melayu" L"مازِرونی" L"नेपाली" L"Nederlands" L"Norsk nynorsk" L"Norsk bokmål" L"Nouormand" L"Diné bizaad" L"Occitan" L"ਪੰਜਾਬੀ" L"Picard" L"Polski" L"پنجابی" L"Português" L"Runa Simi" L"Română" L"Русский" L"संस्कृतम्" L"Srpskohrvatski / српскохрватски" L"සිංහල" L"Simple English" L"Slovenčina" L"Slovenščina" L"Shqip" L"Српски / srpski" L"Svenska" L"தமிழ்" L"Тоҷикӣ" L"ไทย" L"Türkçe" L"Українська" L"اردو" L"Oʻzbekcha" L"Tiếng Việt" L"Winaray" L"ייִדיש" L"中文" L"文言" L"Bân-lâm-gú" L"粵語", L"INTERNATIONAL", MB_ICONINFORMATION); return 0; } |
XPでの実行結果
![]()
Windows8での実行結果
コンソールで表示
wprintf()などで上のプログラムの文字列を表示しようとしてもほとんど表示できない。CRTは内部でマルチバイトにしてしまうためだとおもわれる。
以下のように強引に書いてもマルチバイトとして表示してしまう。
|
1 2 3 4 5 |
WriteFile(GetStdHandle(STD_OUTPUT_HANDLE), p, wcslen(p)*2, &d, NULL); |
もともとコンソールはワイド文字仕様になっていないものと思われる。
Ubuntuのコンソールで実験
gccで上のプログラムを普通にコンパイルしても–input-charset=utf8 –exec-charset=utf8などのオプションをつけても以下のようにちゃんと表示されなかった。catなどではちゃんとutf8ファイルを表示出きるのでできると思うがいまはスルー。
|
1 2 3 |
$ ./a.out Afrikaans????Aragon?s???????Aymar aru?????????Boarisch???????????????????? (???????????)???????????????BrezhonegBosanskiCatal?Cebuano??????e?tina???????DanskDeutsch????????EnglishEsperantoEspa?olEestiEuskara?????SuomiFran?aisGalegoGaelg???????????Hrvatski???????Bahasa IndonesiaIlokano?slenskaItalianoBasa Jawa???????????????????????-???????LatinaL?tzebuergeschLietuvi?Latga?uLatvie?u?????????????????????Bahasa Melayu??????????????NederlandsNorsk nynorskNorsk bokm?lNouormandDin? bizaadOccitan??????PicardPolski??????Portugu?sRuna SimiRom?n?????????????????Srpskohrvatski / ???????????????????Simple EnglishSloven?inaSloven??inaShqip?????? / srpskiSvenska??????????????T?rk?e??????????????O?zbekchaTi?ng Vi?tWinaray??????????B?n-l?m-g??? $ |